一、单机数据库及持久化
1.服务器中的数据库
struct redisServer{
//一个数组,保存所有数据库
redisDb *db;
//数据库数量
int dbnum;//默认16
//AOF缓冲区
sds aof_buf;
//一个链表,保存所有客户端状态
list *clients;
//...
};
struct redisDb {
//数据库键空间,保存所有键值对
dict *dict;
//过期字典,保存键的过期时间
dict *expires;
//...
};
struct redisClient {
//客户端当前使用的一个数据库元素
redisDb *db;
//套接字描述符
int fd;
//...
};
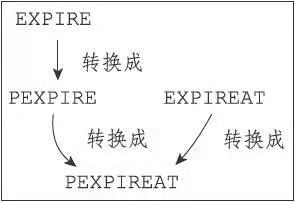
键可以设置过期时间(EXPIRE,PEXPIRE,EXPIREAT,PEXPIREAT),前三个底层都是调用了PEXPIREAT
 PERSIST可以移除一个键的过期时间
过期键存在定时删除(到达指定时间删除)、惰性删除(每次取键值时判断过期并删除)、定期删除(每隔固定时间删除),Redis使用惰性删除和定期删除结合的策略
执行SAVE或者BGSAVE产生的RDB文件不包含过期键
执行BGREWRITEAOF重写的AOF文件不含过期键
当一个过期键被删除时,服务器会追加一条DEL命令到AOF文件末尾
从库不会主动删除过期键,只会等主节点发送DEL命令后再处理
PERSIST可以移除一个键的过期时间
过期键存在定时删除(到达指定时间删除)、惰性删除(每次取键值时判断过期并删除)、定期删除(每隔固定时间删除),Redis使用惰性删除和定期删除结合的策略
执行SAVE或者BGSAVE产生的RDB文件不包含过期键
执行BGREWRITEAOF重写的AOF文件不含过期键
当一个过期键被删除时,服务器会追加一条DEL命令到AOF文件末尾
从库不会主动删除过期键,只会等主节点发送DEL命令后再处理
2.RDB持久化
数据库会持久化到RDB文件中,以压缩后的二进制格式保存
SAVE命令会阻塞Redis服务进程,BGSAVE派生出子进程保存数据
Redis服务器启动时,会检查RDB文件并决定是否从中载入数据
如果开启了AOF持久化,优先使用AOF文件还原数据库状态
通过配置不同的自动保存策略,Redis服务可以在满足不同条件下自动进行BGSAVE操作
3.AOF持久化(Append Only File)
通过保存Redis服务器所执行的写命令来记录数据库状态
追加:当AOF持久化功能开启时,相关写命令会以协议的格式追加到服务器状态的aof_buf缓冲区末尾
写入:写入策略有appendfsync选项配置,always-同步写入AOF文件,everysec-每个事件中都写入缓冲区,但每秒同步一次AOF文件,no-只写入到缓冲区,何时同步AOF由系统决定。重点在于何时调用fsync强制把缓冲区内容写入到AOF文件。always是每次都调;everysec是每秒调一次;no是佛系调用,由操作系统的缓存策略决定何时写入到文件中
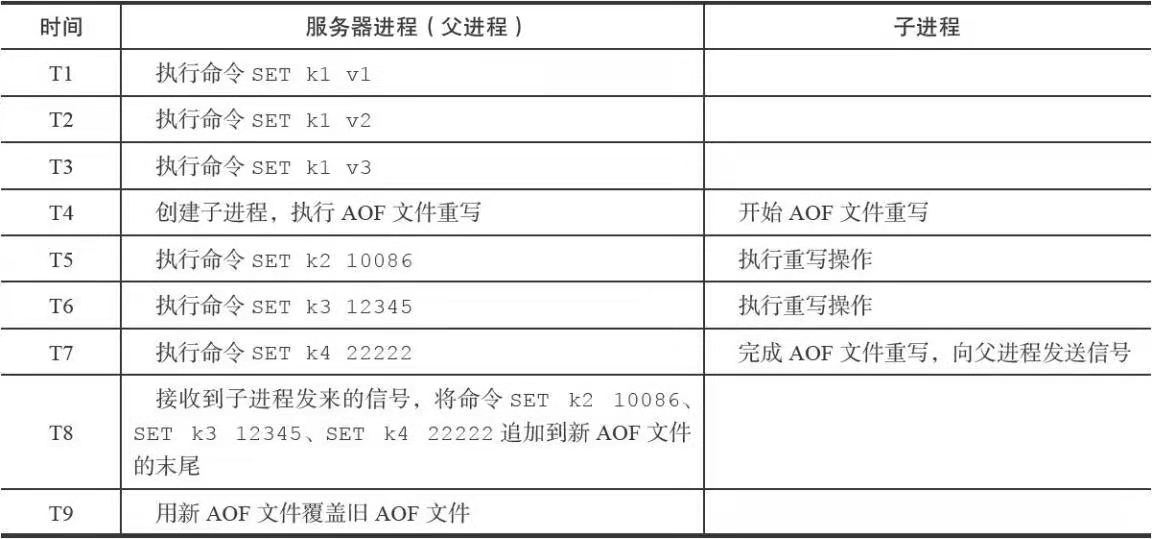
AOF重写:为了避免AOF文件体积过大,采用新旧两个AOF文件来保存数据库状态,但是新文件不包含冗余指令。具体实现原理就是根据服务器当前状态,遍历数据后把数据当前的状态用最小指令写入新的AOF文件。重写期间,可能会对列表、哈希表、集合、有序集合根据配置的最大单次重写数量分批实现命令
BGREWRITEAOF会以后台方式执行AOF重写,在此期间Redis服务器通过维护AOF重写缓冲区保证最终数据一致。
一个AOF文件后台重写过程的举例
二、多机数据库实现
1.复制(master-slave)
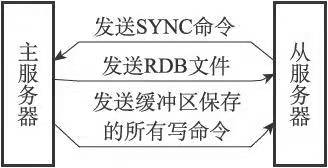
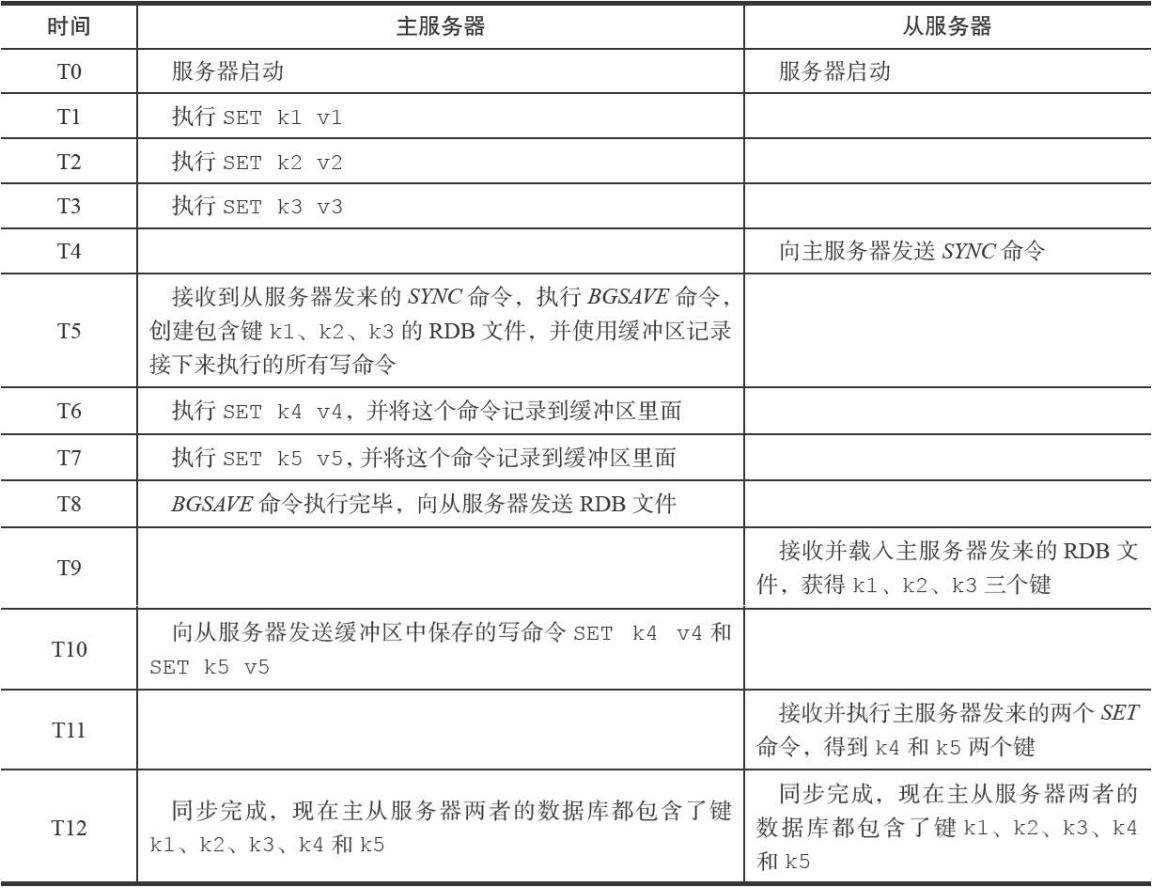
同步:客户端向从服务器发送SLAVEOF命令要求复制主服务器时,先进行同步(sync)操作
同步的过程:
 命令传播:主服务器的数据更新时,需要发送命令给从服务器更新数据
Redis从2.8版本开始使用PSYNC代替SYNC命令实现同步操作,避免在断线重连等场景下因为SYNC操作带来的额外数据传递和资源开销
PSYNC的完整重同步:跟SYNC基本一样
PSYNC的部分重同步:断线重连后只传递断线期间发生的数据更新
命令传播:主服务器的数据更新时,需要发送命令给从服务器更新数据
Redis从2.8版本开始使用PSYNC代替SYNC命令实现同步操作,避免在断线重连等场景下因为SYNC操作带来的额外数据传递和资源开销
PSYNC的完整重同步:跟SYNC基本一样
PSYNC的部分重同步:断线重连后只传递断线期间发生的数据更新
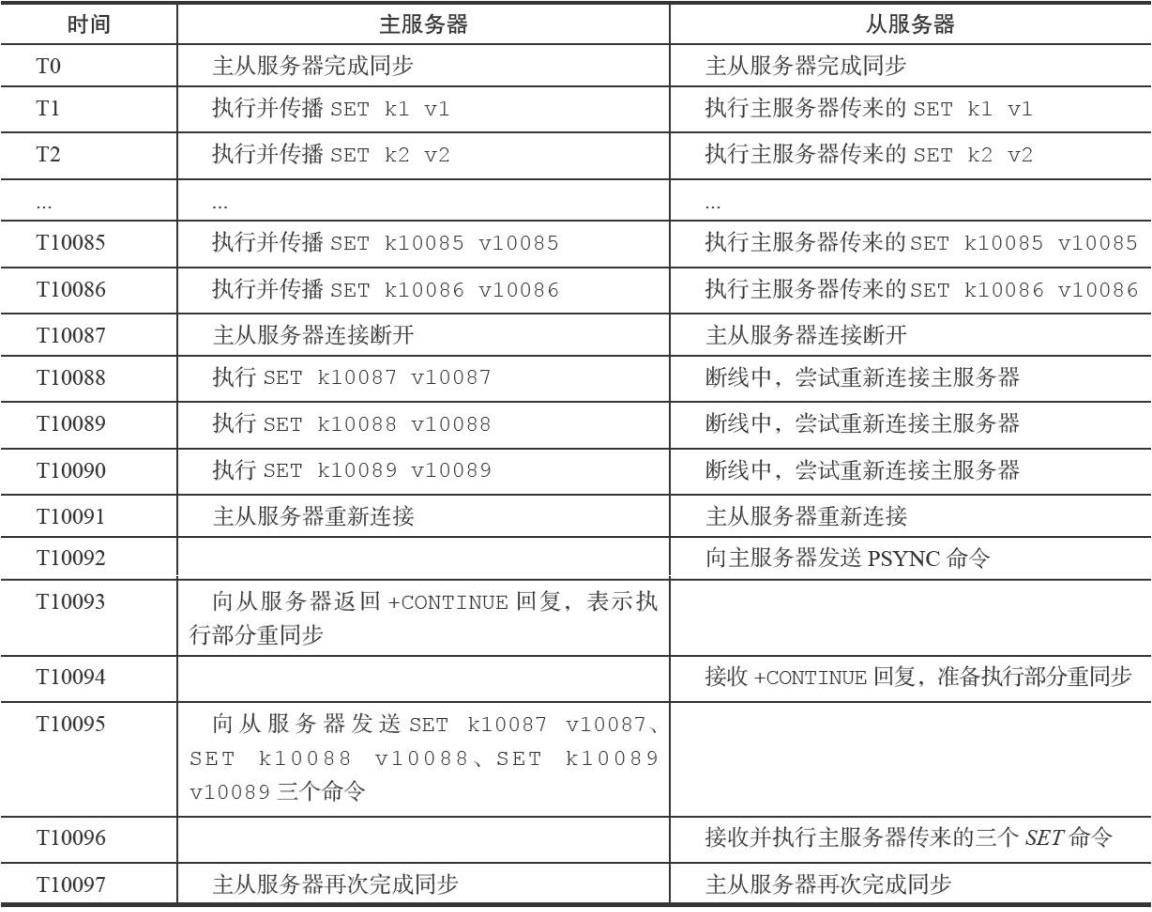 部分重同步,依赖复制偏移量、复制积压缓冲区和服务器运行ID三个部分实现
主从服务器都维护了自己的复制偏移量(offset),用于在部分重同步时比对需要重传的数据。每次传递N字节的数据给从服务器时,主从对应的偏移量都需要加N
复制积压缓冲区维护了一段时间内主服务器的更新操作(先进先出的FIFO队列,默认1MB),包含每个字节对应的复制偏移量
部分重传时,先判断需要重传的offset是否在复制积压缓冲区,如果有则从缓冲区读取数据进行更新;如果对应offset的数据已经被缓冲区移除,则进行完整重同步操作
在具体运维环境中,需要评估自己业务量所需的复制积压缓冲区的内存大小,可以参考2×每秒写入字节数的量来设置
服务器的运行ID,断线重连时用服务器的运行ID判断是否是之前复制的主服务器,如果是则执行部分重同步操作的策略,否则进行完整重同步
部分重同步,依赖复制偏移量、复制积压缓冲区和服务器运行ID三个部分实现
主从服务器都维护了自己的复制偏移量(offset),用于在部分重同步时比对需要重传的数据。每次传递N字节的数据给从服务器时,主从对应的偏移量都需要加N
复制积压缓冲区维护了一段时间内主服务器的更新操作(先进先出的FIFO队列,默认1MB),包含每个字节对应的复制偏移量
部分重传时,先判断需要重传的offset是否在复制积压缓冲区,如果有则从缓冲区读取数据进行更新;如果对应offset的数据已经被缓冲区移除,则进行完整重同步操作
在具体运维环境中,需要评估自己业务量所需的复制积压缓冲区的内存大小,可以参考2×每秒写入字节数的量来设置
服务器的运行ID,断线重连时用服务器的运行ID判断是否是之前复制的主服务器,如果是则执行部分重同步操作的策略,否则进行完整重同步
2.哨兵模式(Sentinel)
由一个或多个哨兵(Sentinel)实例组成的哨兵系统监视任意多个主服务器及属下的所有从服务器。当所监视的主服务器下线时,自动从对应主服务器的从服务器中选举某个从服务器并提升为主服务器处理后续命令请求
Sentinel模式下启动,会加载对应的专用代码和指令
默认情况下,Sentinel每隔一秒向所有创建命令链接的实例发送PING
命令,并通过返回的结果判断实例是否在线
如果一个主服务器实例在down-after-milliseconds时间内,连续向Sentinel返回无效回复,则Sentinel会修改对应实例的状态为主观下线
当其他Sentinel也返回认为该实例处于主观下线或者客观下线的结果时,根据结果数量断定实例是否客观下线,如果确定为客观下线,则对主服务器进行故障转移
多个Sentinel需要进行过半选举选择执行故障转移的领头Sentinel,原则是最先请求选举的获胜
领头的Sentinel根据特定原则(状态正常、最近响应、最小ID依次筛选)选择某个从服务器为主服务器,并将其他从服务器的复制目标设置为新的主服务器。如果此后原主服务器重新上线,则自动成为新的主服务器的从服务器
3.集群(cluster)模式
通过分片进行数据共享,可以通过槽指派重新分片,所有数据都保存在槽中(总共16384个槽)
多个节点最初都相互独立,只有通过发送CLUSTER MEET 进行握手后才会加入一个集群中
当所有16384个槽都被节点处理时,集群才会上线,否则就是下线状态
//节点结构
typedef struct clusterNode {
//...
unsigned char slots[16384/8];
int numslots;
//...
} clusterNode;
//集群状态
typedef struct clusterState {
//...
clusterNode *slots[16384] //每个数组项指向该槽所处理的clusterNode节点的指针
//...
} clusterState;
每个节点记录了节点需要处理的槽信息。slots属性是个16384位的二进制位,数值为1的索引位对应的槽被当前节点处理,numslots属性记录当前节点处理的槽数
不同节点之间相互传递自己处理的槽信息,并且保存接收到的其他节点处理的槽信息到自己的slots属性中,每个节点都知道某个槽应该由哪个节点处理
节点收到客户端的请求时,计算相应键所在的槽,判断是否由自己处理,如果不是则转发请求到相应的节点处理
节点都使用0号数据库
节点可以通过重新分片操作对槽进行节点的指派,在此期间被迁移的槽如果没找到新请求需要处理的键,需要返回ASK错误并把请求引导向目标节点重新处理
ASKING命令只被接下来的请求处理一次并移除
每个节点都会维护一系列下线报告,如果根据各节点的反馈判断某个节点下线后,将该下线的节点标记为已下线(FAIL)
主节点下线后,该节点所属的从节点也按照选举算法选举新的主节点并进行故障转移
上一篇Redis学习笔记——数据结构